
Share
Become a Data Engineer
Welcome to the World of Data Engineering with Microsoft Fabric

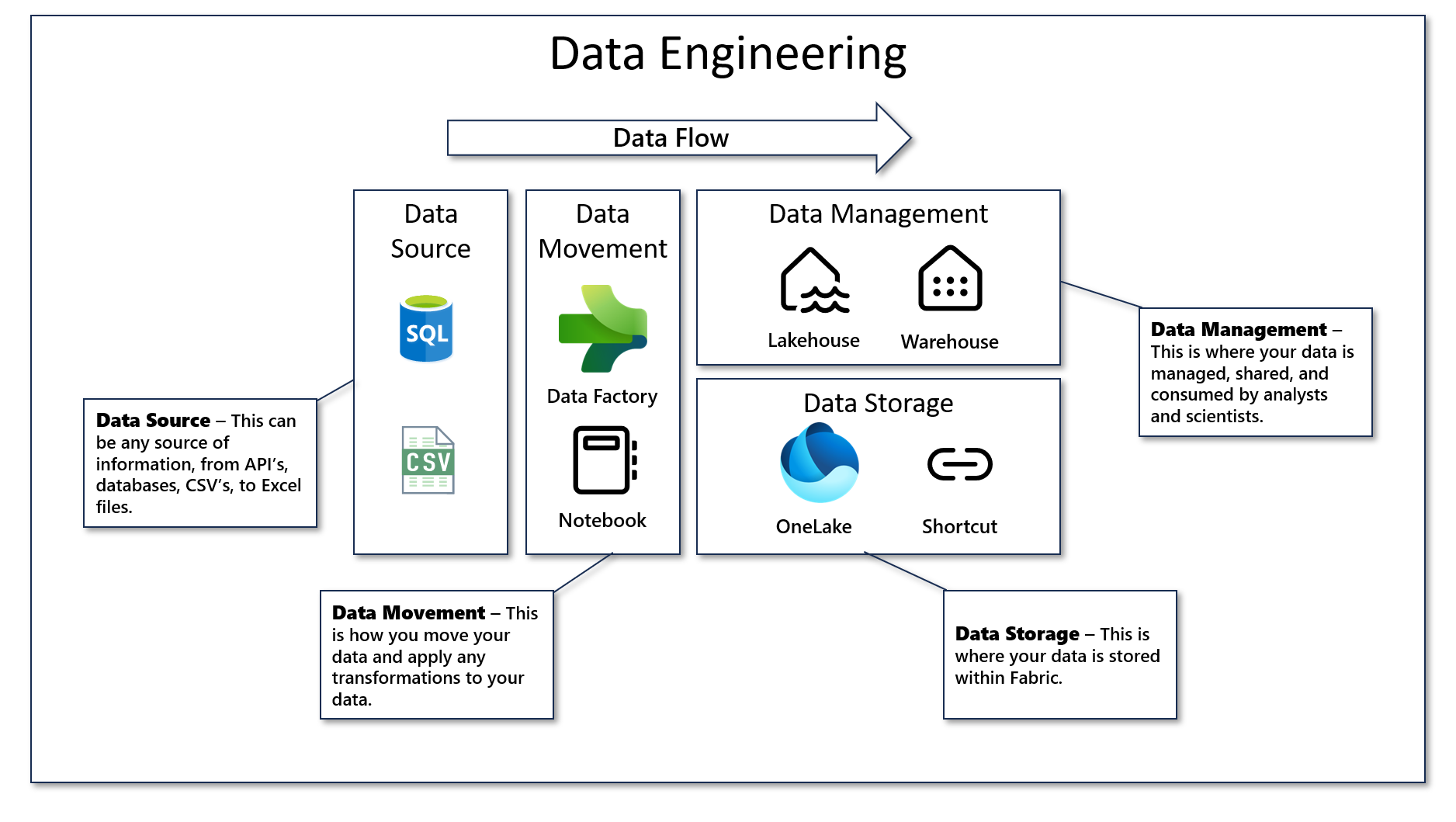
Welcome to the world of data engineering, where the landscape is rich with opportunities to harness the power of data. Whether you're a small business or an enterprise, having a robust data engineering solution is essential for unlocking insights and driving growth. Let's dive into a comprehensive data engineering solution with Microsoft Fabric, which includes a data warehouse, a Lakehouse, a pipeline, a notebook, and a shortcut. Each component is crucial in the data engineering process, contributing to a seamless and efficient workflow.
Overview
In this blog post, we will explore the comprehensive data engineering solutions offered by Microsoft Fabric. We’ll delve into the following key components:
- Data Warehouse: Learn how to set up and utilize a robust, cloud-native data warehouse to store, retrieve, and analyze large volumes of structured data efficiently.
- Lakehouse: Discover the hybrid architecture that combines the flexibility of a data lake with the performance of a data warehouse, enabling seamless management of both structured and unstructured data.
- OneLake: Understand the centralized storage solution that supports all types of data, ensuring easy accessibility, security, and readiness for analysis.
- Shortcuts: Explore how to eliminate data duplication and improve data governance by centrally defining and managing data assets4.
- Data Pipelines: Learn to design, implement, and maintain automated data pipelines that ensure smooth data flow from various sources into your data warehouse and Lakehouse.
- Notebooks: Utilize industry-standard tools to manage ETL processes, transforming raw data into valuable insights through collaborative coding environments.
By the end of this post, you’ll have a clear understanding of how to leverage Microsoft Fabric to create a seamless and efficient data engineering workflow that maximizes the value of your data.
Guide:
1. Understand the Basics: Familiarize yourself with the fundamental concepts of data engineering. Explore online resources, courses, and tutorials to build a strong foundation. Microsoft Fabric offers extensive documentation and learning paths to help you get started.
2. Set Up Your Environment: Ensure you have access to the necessary tools and platforms. With Microsoft Fabric, you can leverage a cohesive suite of data engineering tools integrated within the Microsoft ecosystem, including cloud services and data engineering software.
Data Movement
Microsoft Fabric Data Factory Pipeline
Orchestration is critical in the data engineering pipeline. A robust data pipeline allows you to manage and automate data loads, ensuring data flows smoothly from various sources into your data warehouse and lakehouse. With Microsoft Fabric's cloud-native data pipelines, you can easily handle even the heaviest workloads, ensuring your data is always up-to-date and ready for analysis.
Guide:
1. Design Your Pipeline: Plan your data pipeline architecture. Identify the data sources, transformation processes, and destinations. Microsoft Fabric provides intuitive tools to help you design and visualize your pipeline.
2. Implement the Pipeline: Use Microsoft Fabric's integrated tools, such as Azure Data Factory, to build and automate your data pipeline. These tools offer seamless integration and powerful automation capabilities.
3. Monitor and Maintain: Regularly monitor your data pipeline to ensure it runs smoothly. Microsoft Fabric includes robust monitoring and logging features to help you implement error handling and troubleshoot issues efficiently.
Next Steps
· Course: Explore Azure Pipelines
· Course: Create a build pipeline with Azure Pipelines
Microsoft Fabric Notebook
Notebooks are your best friend when managing ETL (Extract, Transform, Load) processes. These industry-standard tools bring the power of programming languages like Python and Scala to your fingertips, allowing you to write, test, and execute code in a collaborative environment. Notebooks support many open-source capabilities, making transforming raw data into valuable insights easier.
Guide:
1. Set Up Your Notebook: Choose a notebook platform, such as Jupyter, Databricks, or Azure Synapse Notebooks.
2. Write ETL Code: Write ETL scripts using programming languages like Python or Scala. Leverage libraries and frameworks to simplify data transformation tasks.
3. Collaborate and Share: Share your notebooks with team members for collaboration. Use version control to track changes and maintain consistency.
Next Steps
· Course: Get started with OneNote
· Resource: OneNote Class Notebook
Data Management
Microsoft Fabric Data Warehouse
Imagine having a robust vault where all your structured data is securely stored, easily accessible, and ready for analysis. This is what a data warehouse in Microsoft Fabric offers. It is an enterprise-scale, cloud-native solution designed to handle large volumes of data while remaining cost-effective for businesses of all sizes. The data warehouse enables you to store, retrieve, and analyze data efficiently, ensuring that your business decisions are always data-driven.
Guide:
1. Set Up Your Data Warehouse: Choose Microsoft Fabric as your cloud provider and set up your data warehouse. Microsoft Fabric integrates seamlessly with other Microsoft tools, providing a cohesive ecosystem for your data needs.
2. Load Data: Import your structured data into the data warehouse. Utilize ETL (Extract, Transform, Load) processes to ensure your data is clean and ready for analysis. Microsoft Fabric offers robust ETL capabilities to streamline this process.
3. Query and Analyze: Use SQL or other query languages to retrieve and analyze your data. Create insightful reports and dashboards using Power BI, which integrates seamlessly with Microsoft Fabric, to visualize your findings and drive informed business decisions.
Next Steps:
· Course: Get started with data warehouses in Microsoft Fabric
· Course: Build A Data Warehouse in Azure
Microsoft Fabric Lakehouse
Next, we have the lakehouse—a hybrid that combines the best of both worlds: a data lake's flexibility and scalability with a data warehouse's performance and reliability. The lakehouse allows you to manage both structured and unstructured data seamlessly. This means you can store raw data in its native format and process it as needed, providing a unified platform for all your data needs.
Guide:
1. Set Up Your Lakehouse: Choose a platform that supports lakehouse architecture, such as Databricks or Azure Synapse Analytics.
2. Store Data: Import both structured and unstructured data into the lakehouse. Ensure data is stored in its native format for flexibility.
3. Process Data: Use data processing tools to transform raw data into a usable format. Leverage the lakehouse's capabilities to handle large-scale data processing tasks.
Next Steps
· Course: Get started with lakehouses in Microsoft Fabric
· Course: Implement a Lakehouse with Microsoft Fabric
Data Storage
OneLake
Microsoft Fabric offers a unified and robust storage solution through OneLake, designed to centralize and streamline your data management. OneLake is the backbone of Microsoft Fabric, providing a scalable, high-performance storage system that supports structured and unstructured data. This integration ensures your data is easily accessible, secure, and ready for analysis.
Guide:
1. Understand the Basics: OneLake is built on top of Azure Data Lake Storage (ADLS) Gen2 and supports any type of file, whether structured or unstructured. It centralizes data storage across different domains and tenants, reducing redundancy and improving efficiency.
2. Set Up Your Environment: Ensure you have access to Microsoft Fabric and OneLake. OneLake integrates seamlessly with other Microsoft tools, providing a cohesive ecosystem for your data needs. It supports managed and unmanaged data storage, offering flexibility in managing your data.
3. Utilize OneLake Features: OneLake offers full Delta support using VertiParq, a powerful feature for tracking data changes. It also integrates with DirectLake, providing robust support for Power BI and enabling easy data discovery and visualization.
4. Monitor and Maintain: OneLake simplifies security while ensuring that sensitive data is kept secure. It provides distributed ownership of data and security, allowing you to manage access and permissions effectively. Please regularly monitor your storage to ensure it meets your performance and security requirements.
By leveraging Microsoft Fabric and OneLake, you can create a unified, efficient, and secure data storage environment that supports your business's analytical needs.
Next Steps
· Course: OneLake, the OneDrive for data
Microsoft Fabric Shortcuts
Let's talk about shortcuts. In data engineering, shortcuts help eliminate data duplication across your ecosystem. You can centrally define and manage data assets using shortcuts, ensuring consistency and reducing redundancy. This improves data quality and streamlines data governance, making it easier to comply with regulatory requirements.
Guide:
1. Define Shortcuts: Identify data assets that can be centrally managed using shortcuts. Create definitions for these assets to ensure consistency.
2. Implement Shortcuts: Use data management tools to implement shortcuts. Ensure that data assets are referenced correctly across your ecosystem.
3. Maintain Data Quality: Regularly review and update shortcuts to maintain data quality. Implement data governance practices to ensure compliance with regulatory requirements.
Next Steps
· Resource: Office cheat sheets
Conclusion
Incorporating a data warehouse, lakehouse, pipeline, notebook, and shortcut into your data engineering strategy with Microsoft Fabric can revolutionize your data handling. Each component brings unique benefits, from efficient data storage and processing to streamlined data management and governance. By leveraging Microsoft Fabric’s comprehensive suite of tools, you can create a seamless and efficient data engineering workflow that maximizes the value of your data. Embrace this powerful solution today and unlock the full potential of your data with Microsoft Fabric.
Next Steps
1. Data Warehouse
· Course: Get started with data warehouses in Microsoft Fabric
· Course: Build A Data Warehouse in Azure
2. Lakehouse
· Course: Get started with lakehouses in Microsoft Fabric
· Course: Implement a Lakehouse with Microsoft Fabric
3. OneLake
· Course: OneLake, the OneDrive for data
4. Shortcuts
· Resource: Office cheat sheets
5. Pipelines
· Course: Explore Azure Pipelines
· Course: Create a build pipeline with Azure Pipelines
6. Notebooks
· Course: Get started with OneNote
· Resource: OneNote Class Notebook

CHRIS WAGNER, MBA MVP
Analytics Architect, Mentor, Leader, and Visionary




